
How KV Caching Works in Large Language Models

Large language models (LLMs) are remarkable at generating coherent text. Behind the scenes, they rely on transformer layers that process tokens sequentially, computing attention scores across all previous tokens. While this gives models long-term context, it comes at a cost: repeated computation for tokens that have already been processed. KV caching is the optimization that solves this problem, making LLMs faster and more efficient.
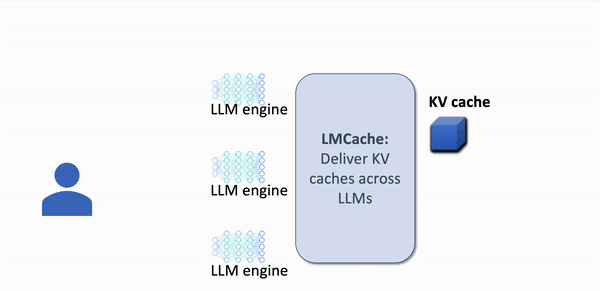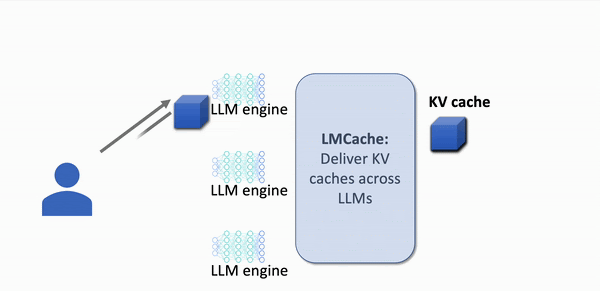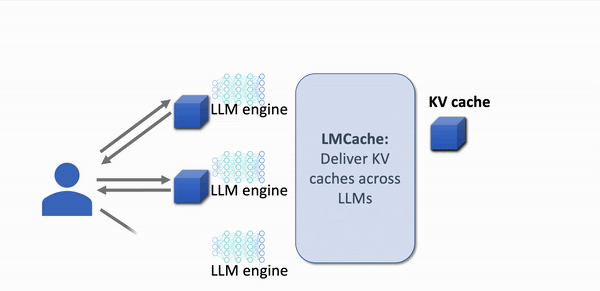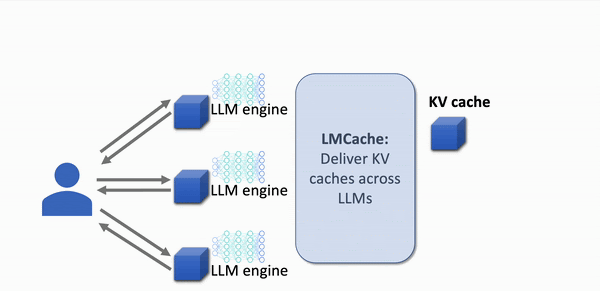
Quick visualisation of KV cache in action
Without KV caching
- All prompt data is computed everytime
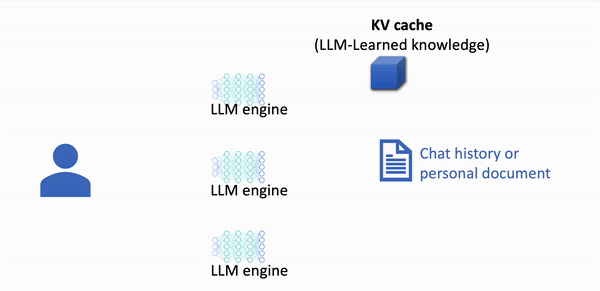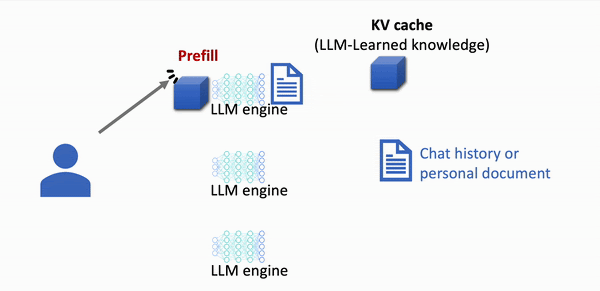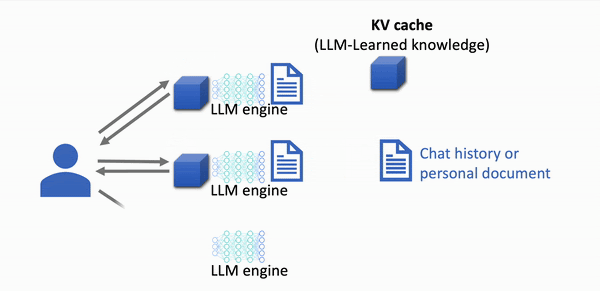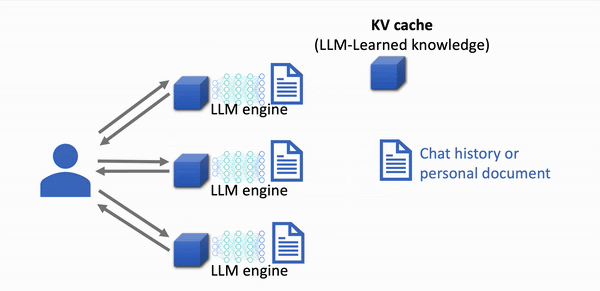
src: https://lmcache.ai
With KV caching
- Cached prompt data is re-used
src: https://lmcache.ai
The Transformer Attention Mechanism
Each transformer layer computes attention using queries (Q), keys (K), and values (V).
- Query (Q): Represents the token you are currently generating or attending from.
- Key (K): Encodes the information of each previous token in a way that can be compared with queries.
- Value (V): Stores the content information of each token that will be aggregated based on attention scores.
Mathematically, attention is computed as:
Attention(Q, K, V) = softmax(Q × K^T / sqrt(d)) × V
Where d is the dimensionality of the hidden states.
- Each token produces one K and one V per layer.
- K and V are matrices shaped
[num_heads, seq_len, head_dim]. - These matrices are what allow the model to “remember” previous tokens.
What KV Caching Is
When generating text sequentially, the model computes K and V for every token at each layer. If a prefix of the input is repeated in multiple requests, recomputing K and V for those tokens is wasteful.
KV caching stores these K and V tensors so that they can be reused for future tokens, avoiding recomputation while producing the same outputs.
Example: KV Caching in Action
Suppose you have a prompt:
System: You are a helpful assistant.
User: What is the capital of France?
- Tokenize and process Each token generates K and V tensors in every layer.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
prompt = "The capital of France is"
inputs = tokenizer(prompt, return_tensors="pt")
# Compute KV cache
outputs = model(**inputs, use_cache=True)
kv_cache = outputs.past_key_values # List of (K, V) tuples for each layer
- Extend the prompt Now, generate the next token with a new query:
new_prompt = " and Germany?"
new_inputs = tokenizer(new_prompt, return_tensors="pt")
# Reuse KV cache
new_outputs = model(**new_inputs, past_key_values=kv_cache, use_cache=True)
- The model reuses the cached K and V for the first part of the sequence.
- Only the new tokens are processed fully.
- Output is identical to recomputing the entire sequence.
How Transformers Use KV Cache Internally
-
Layer-level storage
- Each transformer layer stores a separate
(K, V)tuple for each token. - The shape is
[num_heads, seq_len, head_dim].
- Each transformer layer stores a separate
-
Attention computation with cache
- New queries are compared with cached K matrices via dot product.
- The resulting attention scores weight the cached V matrices to compute outputs.
-
Multi-turn conversations
- Cached K/V states can persist across turns in a chat.
- Only new tokens trigger full computation, making chat sessions more efficient.
LMCache: Advanced KV Caching for vLLM
LMCache is a library designed to store and reuse KV caches efficiently across GPU, CPU, and disk.
Features:
- Stores K/V tensors for repeated prompts.
- Supports multi-turn conversations and retrieval-augmented generation (RAG).
- Reduces latency and GPU usage.
Example usage:
from vllm import LLM
from lmcache import LMCache
llm = LLM("gpt2")
cache = LMCache(storage="disk", path="/tmp/kv_cache")
prompt = "The capital of France is"
outputs = llm.generate(prompt, use_cache=True, cache=cache)
# Next turn
new_prompt = " and Germany?"
new_outputs = llm.generate(new_prompt, use_cache=True, cache=cache)
LMCache handles storing and retrieving K/V tensors transparently.
Visualizing KV Caching
- Prompt A → KV cache generated.
- Prompt B → Reuse KV cache from Prompt A.
- Only new tokens go through full attention computation.
This can speed up multi-turn conversations by 5-10x depending on sequence length.
Key Takeaways
- K and V tensors encode the memory of each token in a transformer layer.
- KV caching reuses these tensors to avoid redundant computation.
- True KV caching requires access to the model internals (open-source or local).
- LMCache shows how caching can be scaled across multi-turn sessions and storage tiers.
- Understanding KV caching is essential for engineers building high-performance LLM applications.
MatterAI builds frontier AI infrastructure for engineering teams — from inference-optimized models to autonomous coding agents and agentic code reviews.
Explore what we're building:
- Orbital IDE — Autonomous AI coding agent with background agents and deep codebase memory
- AI Code Reviews — Agentic pre-commit reviews across GitHub, GitLab, and Bitbucket
- Axon Models — Frontier-grade reasoning models at 70% lower inference cost
Share this Article:
More Articles

Data Annealing: The Hidden Optimization Layer Behind Modern AI Systems
Modern AI systems are no longer trained on static datasets. Frontier models continuously reshape, refine, replay, and optimize data throughout training — creating a new paradigm we call Data Annealing.

The Economics of AI Agents: How Companies Are Reducing AI Inference Costs by 70%
AI agents are becoming core infrastructure inside modern companies, but inference costs are scaling faster than most teams expect. Here's why AI agents become expensive — and how organizations are reducing operational AI costs by up to 70%.

How We Rebuilt the Context Layer Behind AI Code Review
Let's dive deep into the most advance and cost effective code reviewer

Introducing Orbital: The low cost AI Coding App Built for Engineers
A full end-to-end alternative to Cursor and Windsurf, powered by Axon LLMs with 2-5x higher usage limits and complete data privacy.

How MatterAI Brings Business Context in Code Reviews to Drive Better Reviews
Discover how MatterAI integrates with Jira and other tools to bring business context into code reviews, enabling more accurate, relevant, and impactful reviews.
Continue Reading
Data Annealing: The Hidden Optimization Layer Behind Modern AI Systems
Modern AI systems are no longer trained on static datasets. Frontier models continuously reshape, refine, replay, and optimize data throughout training — creating a new paradigm we call Data Annealing.
The Economics of AI Agents: How Companies Are Reducing AI Inference Costs by 70%
AI agents are becoming core infrastructure inside modern companies, but inference costs are scaling faster than most teams expect. Here's why AI agents become expensive — and how organizations are reducing operational AI costs by up to 70%.
How We Rebuilt the Context Layer Behind AI Code Review
Let's dive deep into the most advance and cost effective code reviewer
Ship Faster. Ship Safer.
Join thousands of engineering teams using MatterAI to autonomously build, review, and deploy code with enterprise-grade precision.