
OrbCode: Semantic Search and Inference Optimization for Claude Code

Claude Code is powerful. But running it at scale without optimization is expensive, slow, and opaque.
OrbCode is a Claude Code plugin that sits between your Claude Code instance and the Anthropic API. It intercepts every request, optimizes it, and gives you full visibility into what's happening — without touching your workflow.
Quick Installation
/plugin marketplace add MatterAIOrg/orbcode
/plugin install orb@matterai-marketplace
OrbCode Analytics
Most teams know their monthly Anthropic bill. They don't know where it's going.
OrbCode's analytics dashboard tracks every session across your Claude Code workflows — in real time.
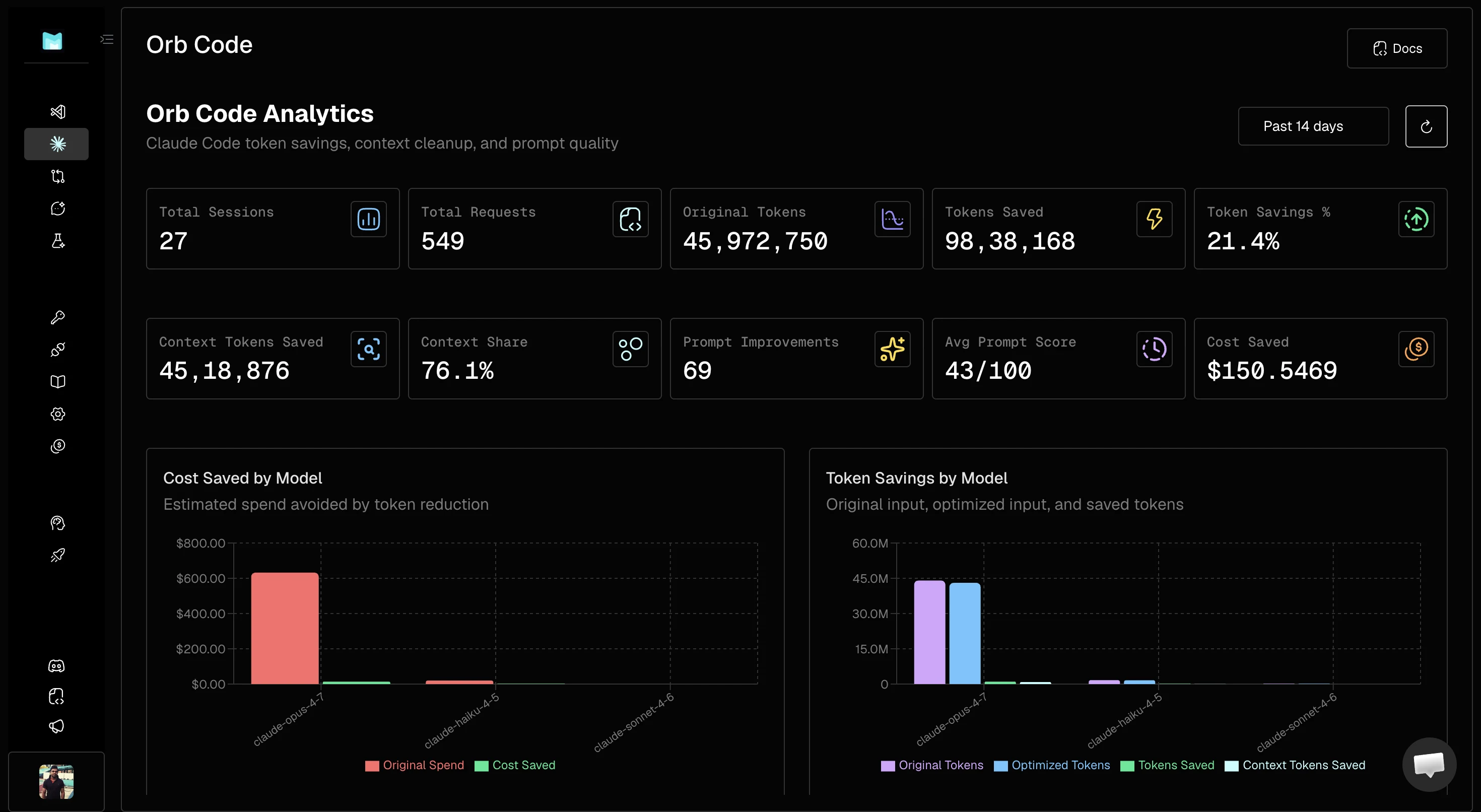
Here's what a real 14-day window looks like in production:
27 sessions, 549 requests— 45.9M original tokens processed9.8M tokens saved— purely from prompt and context optimization passes69 prompt improvements, avg prompt score 43/100 — significant headroom, every session moves the baseline up$150.55 savedin 14 days from a single developer's workflow
The Cost Saved by Model breakdown tells you where your spend is actually concentrated. In the data above, claude-opus-4-7 dominates original spend — and dominates savings too. That's the model routing signal: if Opus is handling tasks that Sonnet could do equivalently, you have a cost lever you're not pulling.
The Problem: Tool Calls Are Inference Overhead
Most teams think of Claude Code cost as "tokens in the response." The real cost is everything before that.
To answer "refactor the auth middleware," Claude Code might grep for "auth," read 12 files, follow import chains, hit dead ends, and retry — all before writing a line of code. Every file read, every grep result, every retry gets injected into the context window and billed.
A single planning phase can quietly consume 50–70% of a session's tokens.
The root cause: Claude Code's default retrieval is keyword search and file traversal. It doesn't understand your codebase — it searches it. That distinction is expensive.
Why Grep Fails at Repository Scale
Claude Code's grep-based retrieval breaks predictably on real engineering queries:
- "Where is WebSocket retry logic?" → grep "retry" returns noise. The actual implementation is
reconnect_with_backoff. - "Find auth middleware" → spread across decorators, a JWT validator, and a session store. None named "auth."
- "Show billing sync flows" → a webhook handler, background job, and third-party adapter with no shared naming.
Each miss forces more tool calls, more file reads, more context injection. Inference cost compounds. Output quality drops.
How OrbCode Works
OrbCode runs a lightweight local proxy at 127.0.0.1:7856. Every Anthropic API request from Claude Code flows through it.
Claude Code
→ Local Proxy (127.0.0.1:7856)
→ MatterAI orbinference API
→ Optimized request
→ Anthropic API → Response
Before inference, OrbCode runs optimization passes across the full request:
Prompt optimization — restructures prompts for clarity, removes redundancy, improves signal quality before tokens are spent.
Tool optimization — tightens tool call structures, eliminates redundant invocations before they execute. A tool call that doesn't happen generates zero tokens.
Context optimization — strips low-relevance content from the context window. Smaller, tighter context improves both cost and output quality.
Semantic retrieval — replaces grep-based results with semantically-retrieved code from OrbCode's vector index. Claude Code gets the right files on the first lookup.
Header and request optimization — modifies request structure and headers where beneficial before hitting the Anthropic API.
Zero changes to your Claude Code setup. No API key modifications. The proxy is fully transparent.
Semantic Repository Indexing
On first run, OrbCode indexes your repository into a vector store. It updates incrementally as files change.
When Claude Code searches for code, OrbCode intercepts the retrieval and returns semantically-matched results — not keyword matches. "Find connection resilience logic" resolves in one lookup instead of a multi-step traverse.
For monorepos and large codebases, this is the difference between a 3-step retrieval and a 30-step one. Fewer steps means less context overhead means cheaper, faster, better inference.
Full Inference Analytics
Most teams know their monthly Anthropic bill. They don't know where it's going.
OrbCode's analytics dashboard gives you complete session-level visibility:
| Metric | What it tells you |
|---|---|
| Total sessions / requests | Workflow volume baseline |
| Original tokens vs. saved | Raw optimization impact |
| Token savings % | Efficiency across task types |
| Context tokens saved | Retrieval overhead reduction |
| Prompt improvement count | How often prompts were restructured |
| Avg prompt score | Prompt quality trending |
| Estimated cost savings | Dollar impact by session |
| Cost saved by model | Sonnet vs. Haiku breakdown |
| Token savings by model | Where to route workloads |
When you can see that repository traversal is consuming 60% of your session tokens, you have an engineering problem with an engineering solution.
What Teams Actually Get
OrbCode's optimization passes reduce token consumption 20–40% on typical Claude Code workflows. Repository-heavy tasks — planning phases, large refactors, monorepo navigation — see the largest gains.
Beyond cost: tighter context means fewer retries. Better retrieval means less wrong-path exploration. Long-running autonomous sessions compound these gains across every planning loop and multi-file reasoning chain.
Install takes minutes. Indexing is automatic. Nothing changes for your engineers.
Installation
Step 1: Add Marketplace
/plugin marketplace add MatterAIOrg/orbcode
Step 2: Install Plugin
/plugin install orb@matterai-marketplace
MatterAI builds frontier AI infrastructure for engineering teams — from inference-optimized models to autonomous coding agents and agentic code reviews.
Explore what we're building:
- Orbital IDE — Autonomous AI coding agent with background agents and deep codebase memory
- AI Code Reviews — Agentic pre-commit reviews across GitHub, GitLab, and Bitbucket
- Axon Models — Frontier-grade reasoning models at 70% lower inference cost
Share this Article:
More Articles

Data Annealing: The Hidden Optimization Layer Behind Modern AI Systems
Modern AI systems are no longer trained on static datasets. Frontier models continuously reshape, refine, replay, and optimize data throughout training — creating a new paradigm we call Data Annealing.

The Economics of AI Agents: How Companies Are Reducing AI Inference Costs by 70%
AI agents are becoming core infrastructure inside modern companies, but inference costs are scaling faster than most teams expect. Here's why AI agents become expensive — and how organizations are reducing operational AI costs by up to 70%.

How We Rebuilt the Context Layer Behind AI Code Review
Let's dive deep into the most advance and cost effective code reviewer

Introducing Orbital: The low cost AI Coding App Built for Engineers
A full end-to-end alternative to Cursor and Windsurf, powered by Axon LLMs with 2-5x higher usage limits and complete data privacy.

How MatterAI Brings Business Context in Code Reviews to Drive Better Reviews
Discover how MatterAI integrates with Jira and other tools to bring business context into code reviews, enabling more accurate, relevant, and impactful reviews.
Continue Reading
Data Annealing: The Hidden Optimization Layer Behind Modern AI Systems
Modern AI systems are no longer trained on static datasets. Frontier models continuously reshape, refine, replay, and optimize data throughout training — creating a new paradigm we call Data Annealing.
The Economics of AI Agents: How Companies Are Reducing AI Inference Costs by 70%
AI agents are becoming core infrastructure inside modern companies, but inference costs are scaling faster than most teams expect. Here's why AI agents become expensive — and how organizations are reducing operational AI costs by up to 70%.
How We Rebuilt the Context Layer Behind AI Code Review
Let's dive deep into the most advance and cost effective code reviewer
Ship Faster. Ship Safer.
Join thousands of engineering teams using MatterAI to autonomously build, review, and deploy code with enterprise-grade precision.